Der Canonical Tag wurde im Februar 2009 von Google eingeführt, um es Seitenbetreibern zu ermöglichen, doppelte Inhalte besser zu handhaben. Hast du zwei Websites mit unterschiedlichen URLs, aber nahezu identischen Inhalten, dann ist der Canonical Tag das geeignete Werkzeug.
In welchen Fällen verwendet man den Canonical Tag?
Eine Startseite ist unter verschiedenen URLs aufrufbar
www.beispiel.de
beispiel.de
www.beispiel.de/index.html
Ein Seite ist mit und ohne Trailing Slash / aufrufbar
www.beispiel.de/
www.beispiel.de
Es sind https-Varianten einer Seite aufrufbar
http://beispiel.de
https://beispiel.de
Inhalte werden zusätzlich auf externen Websites veröffentlicht
www.beispiel.de/thema1
www.example.com/thema1
In diesen Fällen redet man von Duplicate Content. Google sieht das nicht gern; das Ziel sollte sein, nur eine bevorzugte URL zu nutzen. Komplexer wird es beispielsweise bei Shops, bei denen durch umfangreiche Sortierfunktionen oftmals sehr viele doppelte Inhalte entstehen.
Canonical URL und SEO
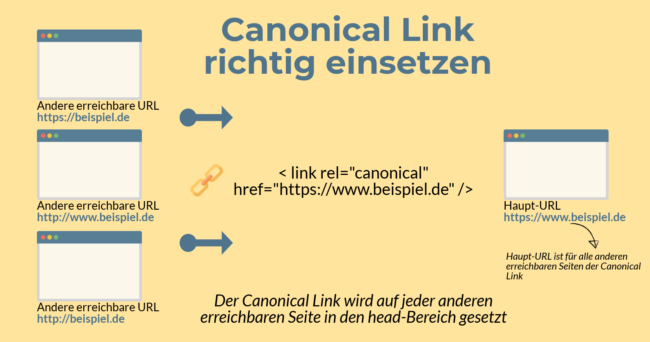
Genau hier kommt dann der Canonical Tag ins Spiel. Mit ihm lässt sich definieren, welches die Originalseite ist. Um beim obigen Beispiel zu bleiben: Die Haupt-URL einer Website soll https://www.beispiel.de sein, ist aber auch unter http://www.beispiel.de aufrufbar. In diesem Fall würde im Quellcode der Seite https://beispiel.de der Canonical Tag auf die Variante mit www. verweisen.
< link rel="canonical" href="https://www.beispiel.de" />
Auf diese Art kann Google kommuniziert werden „hier liegt eine Dublette vor, aber unter der angegebenen URL findet sich das Original. Bitte berücksichtige nur die angegebene Version im Quellcode“. Es sollte auch immer die absolute URL (mit https://) angegeben werden. Eingesetzt wird der Canonical Tag im Head-Bereich der Seite, nicht im Body. Die Seite, die den Canonical Tag im Quellcode zeigt, wird dann nicht in den Suchergebnissen auftauchen! Google selbst zeigt hier auch Möglichkeiten auf, wie man doppelte Inhalte zusammenfasst.
Wie man den Canonical Link einsetzt
Als Randnotiz ist noch anzumerken, dass der Canonical Tag gar kein Tag ist. Warum sich der Begriff hauptsächlich im Deutschen eingebürgert hat ist nicht ganz klar, Google hat ihn korrekt als Canonical URL bzw. Canonical Link vorgestellt.
Auf was muss man beim Einsatz der Canonical URL achten?
Aufpassen muss man, wenn man mit noindex arbeitet. Werden eine kanonische URL und das noindex Attribut gleichzeitig genutzt, besteht das Risiko, dass das noindex Attribut auf die kanonisierte URL angewandt wird und somit genau das Gegenteil vom eigentlich gewünschten Ziel eintritt: Auf die Originalseite wird noindex übertragen und sie verschwindet aus dem Google Index. Aus SEO-Sicht kann das schnell zum Supergau werden.
Auch wichtig zu wissen ist, dass man nur einen Canonical Tag vergibt. Sollten sich mehrere Canonical Verweise auf einer Seite befinden, werden diese schlichtweg ignoriert. Des weiteren sollten nummerierte Seiten (rel="next" und rel="previous") nicht mit einem Canonical Tag versehen werden, da es sich hier nicht um doppelte Inhalte handelt.
Hoffentlich konnte ich Dir das Thema „Canonical URL“ verständlich beschreiben. Falls Du Fragen hast, kannst Du diese gerne in die Kommentare schreiben!
Was ist der Canonical Tag?
Der Canonical Tag wurde im Februar 2009 von Google eingeführt, um es Seitenbetreibern zu ermöglichen, doppelte Inhalte besser zu handhaben. Hast du zwei Websites mit unterschiedlichen URLs, aber nahezu identischen Inhalten, dann ist der Canonical Tag das geeignete Werkzeug.
In welchen Fällen verwendet man den Canonical Tag?
Eine Startseite ist unter verschiedenen URLs aufrufbar
www.beispiel.de
beispiel.de
www.beispiel.de/index.html
Ein Seite ist mit und ohne Trailing Slash / aufrufbar
www.beispiel.de/
www.beispiel.de
Es sind https-Varianten einer Seite aufrufbar
http://beispiel.de
https://beispiel.de
Inhalte werden zusätzlich auf externen Websites veröffentlicht
www.beispiel.de/thema1
www.example.com/thema1
In diesen Fällen redet man von Duplicate Content. Google sieht das nicht gern; das Ziel sollte sein, nur eine bevorzugte URL zu nutzen. Komplexer wird es beispielsweise bei Shops, bei denen durch umfangreiche Sortierfunktionen oftmals sehr viele doppelte Inhalte entstehen.
Canonical URL und SEO
Genau hier kommt dann der Canonical Tag ins Spiel. Mit ihm lässt sich definieren, welches die Originalseite ist.
Um beim obigen Beispiel zu bleiben: Die Haupt-URL einer Website soll https://www.beispiel.de sein, ist aber auch unter http://www.beispiel.de aufrufbar. In diesem Fall würde im Quellcode der Seite https://beispiel.de der Canonical Tag auf die Variante mit www. verweisen.
< link rel="canonical" href="https://www.beispiel.de" />
Auf diese Art kann Google kommuniziert werden „hier liegt eine Dublette vor, aber unter der angegebenen URL findet sich das Original. Bitte berücksichtige nur die angegebene Version im Quellcode“. Es sollte auch immer die absolute URL (mit https://) angegeben werden. Eingesetzt wird der Canonical Tag im Head-Bereich der Seite, nicht im Body. Die Seite, die den Canonical Tag im Quellcode zeigt, wird dann nicht in den Suchergebnissen auftauchen!
Google selbst zeigt hier auch Möglichkeiten auf, wie man doppelte Inhalte zusammenfasst.
Wie man den Canonical Link einsetzt
Als Randnotiz ist noch anzumerken, dass der Canonical Tag gar kein Tag ist. Warum sich der Begriff hauptsächlich im Deutschen eingebürgert hat ist nicht ganz klar, Google hat ihn korrekt als Canonical URL bzw. Canonical Link vorgestellt.
Auf was muss man beim Einsatz der Canonical URL achten?
Aufpassen muss man, wenn man mit noindex arbeitet. Werden eine kanonische URL und das noindex Attribut gleichzeitig genutzt, besteht das Risiko, dass das noindex Attribut auf die kanonisierte URL angewandt wird und somit genau das Gegenteil vom eigentlich gewünschten Ziel eintritt: Auf die Originalseite wird noindex übertragen und sie verschwindet aus dem Google Index. Aus SEO-Sicht kann das schnell zum Supergau werden.
Auch wichtig zu wissen ist, dass man nur einen Canonical Tag vergibt. Sollten sich mehrere Canonical Verweise auf einer Seite befinden, werden diese schlichtweg ignoriert.
Des weiteren sollten nummerierte Seiten (rel="next" und rel="previous") nicht mit einem Canonical Tag versehen werden, da es sich hier nicht um doppelte Inhalte handelt.
Weitere typische Fehler beim Einsatz der Canonical URL und deren Behebung zeigt Google selbst auf.
Hoffentlich konnte ich Dir das Thema „Canonical URL“ verständlich beschreiben. Falls Du Fragen hast, kannst Du diese gerne in die Kommentare schreiben!
Als wir beschlossen, unsere Konferenz von einer Präsenzveranstaltung zu einem virtuellen Event umzuwandeln, hat sich das eigentlich wie ein „downgrade“ angefühlt. Eine




Eine Antwort